Investing in Astronomer
Update since we invested (March 2022)
So much has happened since we led the Series A for Astronomer. Here is a brief snippet:
- Insight Partners, Salesforce Ventures, and Meritech led our Series C, with George Mathews joining us!
- Datakin joins Astronomer!, the developers of the very popular OpenLineage framework for data lineage collection and analysis
- Sutter Hill led our Series B in Dec 2020 and Scott Yara joined us!
- Airflow surpassed 25K stars on Github, 8M+ monthly downloads, 1.9K+ contributors.
The backstory of our 2020 Series A lead investment into Astronomer.

Ten years ago, the modern enterprise stack looked quite a bit different. Teams of network admins managing data centers, running one application per server, deploying monolithic services, through waterfall processes, with staged releases managed by an entire role labeled “release manager.”
Today, we have multi and hybrid clouds, serverless services, continuous integration, and deployment, running infrastructure-as-code, with DevOps and SRE fighting to keep up with the rapid scale.
Companies are building more dynamic, multi-platform, complex infrastructures than ever. We see the ‘-aaS’ of the application, data, runtime, and virtualization layers. Modern architectures are forcing extensibility to work with any number of mixed and matched services, and fully managed services, effectively leaving operations and scale to the service providers, are becoming the golden standard.
With limited engineering budgets and resource constraints, CTOs and VP Engs are increasingly looking for ways to free up their teams. They’re moving from manual, time-consuming, repetitive work to programmatic workflows, where infrastructure and services are written as code and abstracted into manageable operators such as SQL or DAGs, owned by developers.
If the 2010s represented a renaissance for what we can build and deliver, the 2020s have begun to represent a shift to how we build and deliver, with a focused intensity on infrastructure, data, and operational productivity.
Every company is now becoming a data company.
The last 12 months, in particular, have been a technology tipping point for businesses in the wake of remote work. Every CIO and CTO has been burdened with the increasing need to leverage data for faster decision making, increased pressures of moving workloads to the cloud, and the realizations of technology investments as a competitive advantage in a digital world. The digital transformation we’ve seen play out over the last few years just compressed the next five years of progress into one.
With that, the data infrastructure has become a focal point in unlocking new velocity and scale. Data engineering teams are now the fastest-growing budget within engineering, and in many organizations, and fastest-growing budget, period.
Every company is now becoming a data company, with the data infrastructure at heart.
Building on a brittle data infrastructure
To best understand an enterprise data infrastructure, any company that relies on multiple data sources to power their business or make critical business decisions needs to rely on some form of data infrastructure and pipelines. These are systems and sequences of tasks that move data from one system to another, transform, process, and store the data for use. Metrics aggregations, instrumentation, experimentation, derived data generation, analytics, machine learning feature computation, business reporting, dashboards, etc, all require the automation of data processes and tasks to process and compute data into required formats.
Traditional approaches to building data infrastructures leveraged heavy ETL (extract, transform, load) tools (Informatica, SAS, Microsoft, Oracle, Talend) built on relational databases that require difficult, time-consuming, and labor-intensive rules and config files. With the introductions of modern application stacks and the massive increase in data and processing required, traditional ETL systems have become overly brittle and slow, unable to keep up with the need for increased scale, modularity, and agility.
The slightly more modern approach to scaling up data pipelines relied on batch processing of jobs through the use of static scripts or jobs that define schedulers to kick off specific tasks, i.e. pulling data from a particular source > running a computation > aggregating with another source > populating the updated aggregations to a data warehouse.
Static by design, data engineers must define relationships between steps in a job, pre-define the expected durations based on the worst-case scenario, and define the run-time schedules, hoping the pipelines run as expected.
But static scripts become more brittle as the scale of dependencies increases. If job stalls or errors for any reason, i.e. a server goes down, an exception is found in a data set, a job takes longer than the expected duration, or a dependent task is stalled, both the data engineering and devops teams have to spend countless hours manually identifying, triaging, and restarting jobs.
There are no systems to programmatically retry, queue, prevent overlapping jobs, enforce timeouts, report errors and metrics in a machine-readable way. Further exacerbating the problem, walking into the office every morning, the first question a data engineer asks is “did all of my jobs run?”, and there is no single source of truth to answer their question.
As the jobs and pipelines grow in number and complexity, data engineering and devops spend most of their time manually monitoring, triaging, and reconfiguring their pipeline to keep data flowing to support the business, resulting in more energy spent on the underlying platforms vs actually running the data pipelines.
Meet Apache Airflow

In 2015, a project at Airbnb, aptly named Airflow, focused on solving the brittle data pipeline problem, replacing cron jobs and legacy ETL systems with a workflow orchestration based infrastructure-as-code, allowing users to programmatically author, schedule, and monitor data pipelines. Believing that when workflows are defined as code, they become more maintainable, versionable, testable, collaborative, and performant.
Airflow today is the largest and most popular data infrastructure open source project in the world. Adopted by the Apache foundation in 2016, promoted to a top-level project in 2019, and as of this writing, has over 25K Github stars, 1900 contributors, more than 8M downloads per mnonth, and is one of the most energetic and passionate open source communities we have ever seen - surpassing Apache Spark in contributors, and Apache Kafka in stars and contributors. Airflow is used by thousands of organizations and hundreds of thousands of data engineers.
Airflow has been reinforced by the community as the standard and leader in data pipeline orchestration. With a mass migration off legacy ETL systems, and the increasing popularity of the Airflow project, companies from F500 to the most emerging brands of all sizes and segments are migrating to Airflow and replacing the need for data engineering and devops teams to spend most of their time managing and maintaining their data pipelines instead of building and scaling up new data pipelines. Handing back the control of pipelines to data engineering from DevOps, removing hours of debugging for failed or slow jobs, expanding the capability of the teams to perform more complex and performant pipelines, and run more jobs, faster, creating real business value.
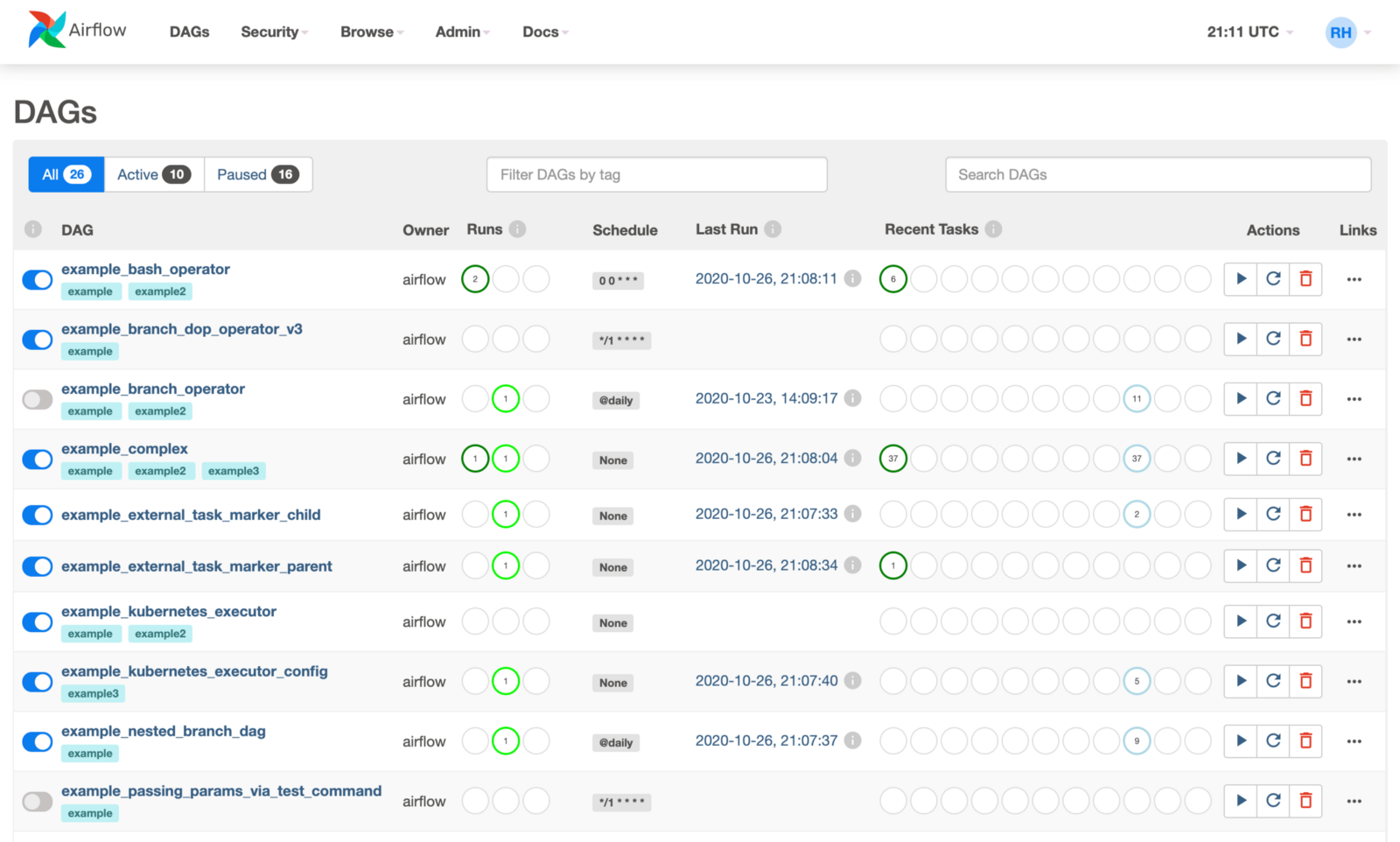
And with the recent release of Airflow 2.0, the team introduced capabilities that go beyond workflow orchestration, to job and task execution, replacing the many, many tasks that teams today overly rely on heavy ETL processes vs moving them into Airflow, and the start of powering mission-critical operational use cases in addition to the core analytics needs.
Meet Astronomer, the modern orchestration platform
In most organizations using Airflow today, it has become one of the most important pieces of infrastructure and changes how data engineering teams operate.
But like most popular open-source solutions, Airflow was designed by the community, for the community. Lacking the necessary enterprise capabilities as it proliferates across an organization such as cloud-native integrations, flexibility to deploy across the various environment and infrastructure setups, high availability, and uptime, performance monitoring, rights access, and security. Teams have to rely on homegrown solutions to solve these challenges as they scale up their installations to enable airflow-as-a-service to internal customers.
That’s until we met Joe and Ry.
Joe, just finishing his tour of duty as CEO at Alpine Data, previously SVP Sales at Greenplum/Pivotal, and Ry, a top contributor to Airflow, saw an early but promising open-source project, with little roadmap and project direction, that could become the central data plane for the data infrastructure. They dedicated themselves to reinvigorating the project, bringing life and focus to its original intentions, realizing that data orchestration and workflow weren’t a part of the data pipeline or infrastructure but was the core of it. They were convinced that Airflow needed to be brought to the enterprises, and there Astronomer was born.
They saw what Airflow could enable for organizations of all sizes; an enterprise-grade solution that was cloud-native, secure, and easy to deploy across any infrastructure or environment, cloud or customers own. Solving the key immediate challenges enterprises face when deploying Airflow and needing high availability, testing and robustness, and extensibility into any infrastructure setup.
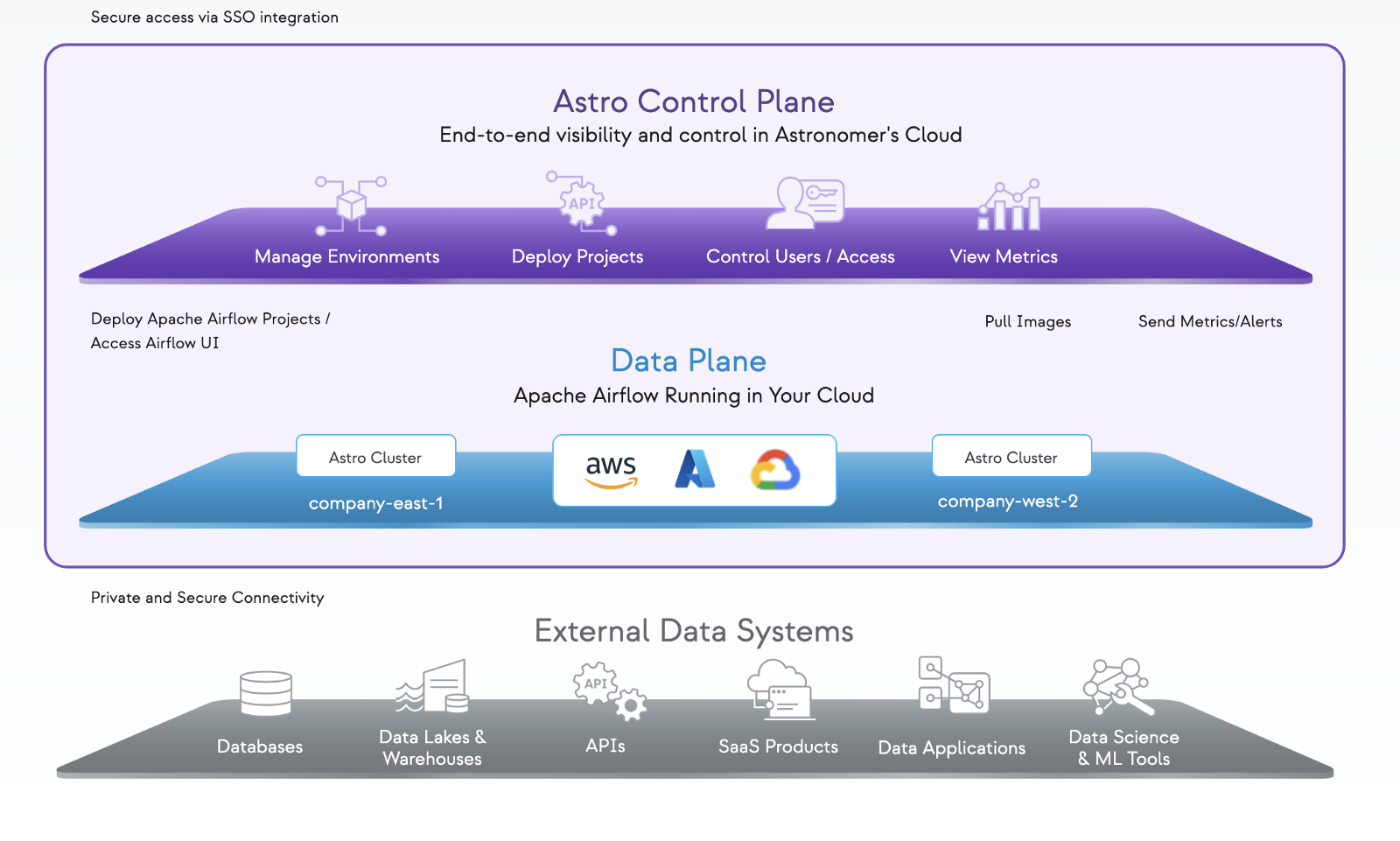
Taking it one step further, deploying Astro Runtime, the managed airflow service, engineered for the cloud, as one integrated, manged platform. Giving enterprises complete visibility into their data universe, including lineage and metadata, through one single pane of glass. Start in less than an hour, scale to millions of tasks.
The result has been astronomical. Customers of all sizes and walks, looking to Astronomer to solve the challenges when trying to scale around availability, robustness, extensibility into their infrastructure, security, and support.
Today their customer base span every industry, segment, and vertical, from the top F500s to the most emerging brands, drawn to the power of the Airflow project and community, and confidence in the enterprise Astronomer platform.
Leading the Series A investment into Astronomer
We’ve long believed the data pipeline was central to the entire enterprise data stack; that workflow and orchestration was the meta-layer responsible for speed, resiliency, and capability of the data infrastructure, with the underlying primitives (connectors, storage, transformations, etc) easily replaced or augmented. As we see the needs of the enterprise increasingly shift from analytical use cases to power the business-critical operational needs, the orchestration layer will prove to be greater than the parts it executes.
As a result, we were fortunate to have been able to lead Astronomer’s Series A in April 2020, joining the board along with our friends at Sierra Ventures. Since then we’ve had the good fortune of being able to welcome our good friends Scott Yara and Sutter Hill who led their Series B, and Insight Partners, Salesforce Ventures, and Meritech with our Series C.
Exciting announcements are always sweeter with one more thing, so we also welcome Laurent, Julien, and the rest of the Datakin team to Astronomer!
This is just the beginning, and we can’t want to share what’s next.