Investing in Decodable
Beginnings of the real-time data enterprise
Data is rapidly transforming every industry. Brick & mortar stores are now turning into micro-distribution centers through real-time inventory management. Organizations are delivering 10x customer experience building up-to-the-second 360 customer views. Complex logistics services having real-time views into operational performance are delivering more on-time than ever before. Data is allowing enterprises to respond faster to changes in their business unlike ever before, and the volume of that data is increasing exponentially. Just having the data stored in your data warehouse is no longer enough.
Real-time data isn’t for the faint of heart
Today, real-time has become the central theme in every data strategy. Whether you are trying to understand user behavior, updating inventory systems as purchases occur across multiple stores, log monitoring to prevent an outage, or connecting on-prem services to the cloud, the majority of use cases can be enabled by filtering, restructuring, parsing, aggregating, or enriching data records. Then coding these transformations into pipelines to drive microservices, machine learning models, operational workflows, or populate datasets.
But building the underlying real-time data infrastructure to power them has always been another story. What originally seemed like a rather straightforward deployment of a few Kafka APIs quickly became an unwieldy hardcore distributed systems problem.
This meant that instead of focusing on building new data pipelines and creating business value, data engineers toil in the time-sink of low-level Java and C++; agonizing over frameworks, data serialization, messaging guarantees, distributed state checkpoint algorithms, pipeline recovery semantics, data backpressure, and schema change management. They’re on the hook for managing petabytes of data daily, at unpredictable volumes and flow rates, across a variety of data types, requiring low-level optimizations to handle the compute demands, with ultra-low processing latencies. Systems must run continuously, without any downtime, flexing up/down with volume, without a quiver of latency. Many Ph.D. theses have been written on this topic, with many more to come.
The underlying infrastructure needed to disappear
We’ve long believed that the only way to unlock real-time data was the underlying infrastructure needed to disappear. Application developers, data engineers, and data scientists should be able to build and deploy a production pipeline in minutes, using industry-standard SQL, without worrying about distributed system theory, message guarantees, or proprietary formats. It had to just work.
Introducing Decodable
We knew we’d found it when we met Eric Sammer and Decodable.
We first met Eric while he was the VP & Distinguished Engineer at Splunk, overseeing the development of their real-time stream processing and infrastructure platform. He joined Splunk through the acquisition of Rocana, as the co-founder and CTO, which was building the ‘real-time data version of Splunk’. Eric was an early employee at Cloudera and even wrote the O’Reilly book on Hadoop Operations (!). A long way of saying Eric was one of the most sought out and respected thought leaders in real-time, distributed systems.
His realization ran deep. Enterprises would be able to deploy real-time data systems at scale only after:
- The underlying, low-level infrastructure effectively disappeared, along with the challenges of managing availability, reliability, and performance
- The real-world complexities of real-time data such as coordinating schema changes, testing pipelines against real data, performing safe deployments, or just knowing their pipelines are alive and healthy, were solved under the hood
- It just worked out of the box by writing SQL
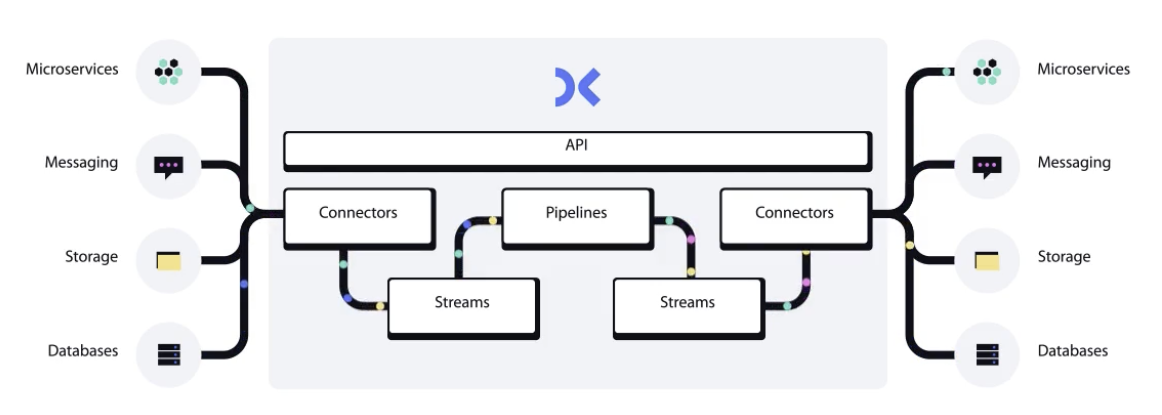
Eric started Decodable with the clarity that developers and teams want to focus on building new real-time applications and capabilities, free from the heavy lifting needed to build and manage infrastructure.. Abstracted away from infrastructure, Decodable’s developer experience needed to be simple and fast — create connections to data sources and sinks, stream data from and to source(s) and sink, and write SQL for the transformation. Decodable uses existing tools and processes, within your existing data platform, across clouds and data infrastructure.
Powered by underlying infrastructure that is invisible and fully managed; Decodable has no nodes, clusters, or services to manage. It can run in the same cloud providers and regions as your existing infrastructure, leaving the platform engineering, DevOps, and SRE to Decodable. It was simple, easy to build and deploy, within minutes not days or weeks, with no proprietary formats, and with just SQL.
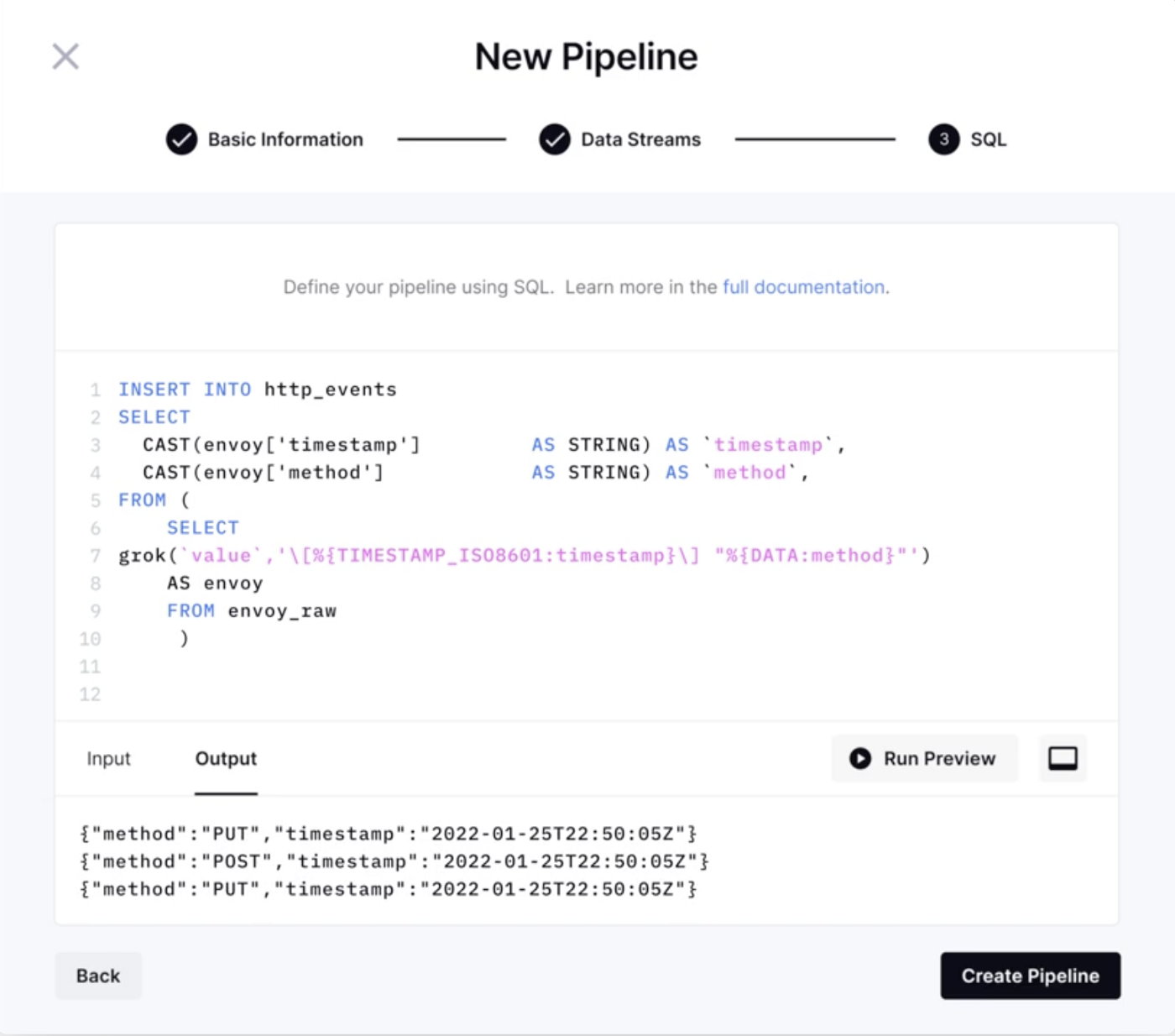
No more low-level code and stitching together complex systems. Build and deploy pipelines in minutes with SQL.
Partnering with Eric & Decodable
Enterprises need to build differentiation to unlock the value of their data, not in the underlying infrastructure to power it. However, that infrastructure is crucial and needs to be powered by a platform that just works as if you had a 25+ data engineering team dedicated to its uptime and performance. It needs to abstract the complexity and allow developers to create new streams in minutes with just SQL.
Eric is building the future of the data infrastructure, and today the platform has moved into general availability!
So we’re thrilled to partner with Eric and announce our Seed and Series A investments into Decodable, co-led with our good friends at Bain Capital. We couldn’t be more excited to support Eric to unlock the power of real-time data.